Chapter 5 CART (Decision Tree)
2021-12-25 updated
Ref: here
Ref: random forest
Decision Tree can handle classification and regression problem. It is also called CART (Classification and Regression Tree). In the following, we will use spam data and Boston house pricing data to demonstrate.
5.1 Classification Tree
library(DAAG) # data sets used in examples and exercise
library(party) # for recursive partitioning
library(rpart) # recursive partitioning and regression trees
library(rpart.plot) # plot rpart models
library(mlbench) # collection of ML benchmark problems
library(caret) # Misc functions for training/plotting models
library(pROC)
library(tree) # classification and regression tree# Getting Email spam data
str(spam7)## 'data.frame': 4601 obs. of 7 variables:
## $ crl.tot: num 278 1028 2259 191 191 ...
## $ dollar : num 0 0.18 0.184 0 0 0 0.054 0 0.203 0.081 ...
## $ bang : num 0.778 0.372 0.276 0.137 0.135 0 0.164 0 0.181 0.244 ...
## $ money : num 0 0.43 0.06 0 0 0 0 0 0.15 0 ...
## $ n000 : num 0 0.43 1.16 0 0 0 0 0 0 0.19 ...
## $ make : num 0 0.21 0.06 0 0 0 0 0 0.15 0.06 ...
## $ yesno : Factor w/ 2 levels "n","y": 2 2 2 2 2 2 2 2 2 2 ...# Data partition
set.seed(1234)
mydata <- spam7
ind <- sample(2, nrow(mydata), replace=TRUE, prob=c(0.5,0.5)) # assign index
train <- mydata[ind == 1,]
test <- mydata[ind == 2,]
tree <- rpart(yesno ~ ., data=train)
rpart.plot(tree)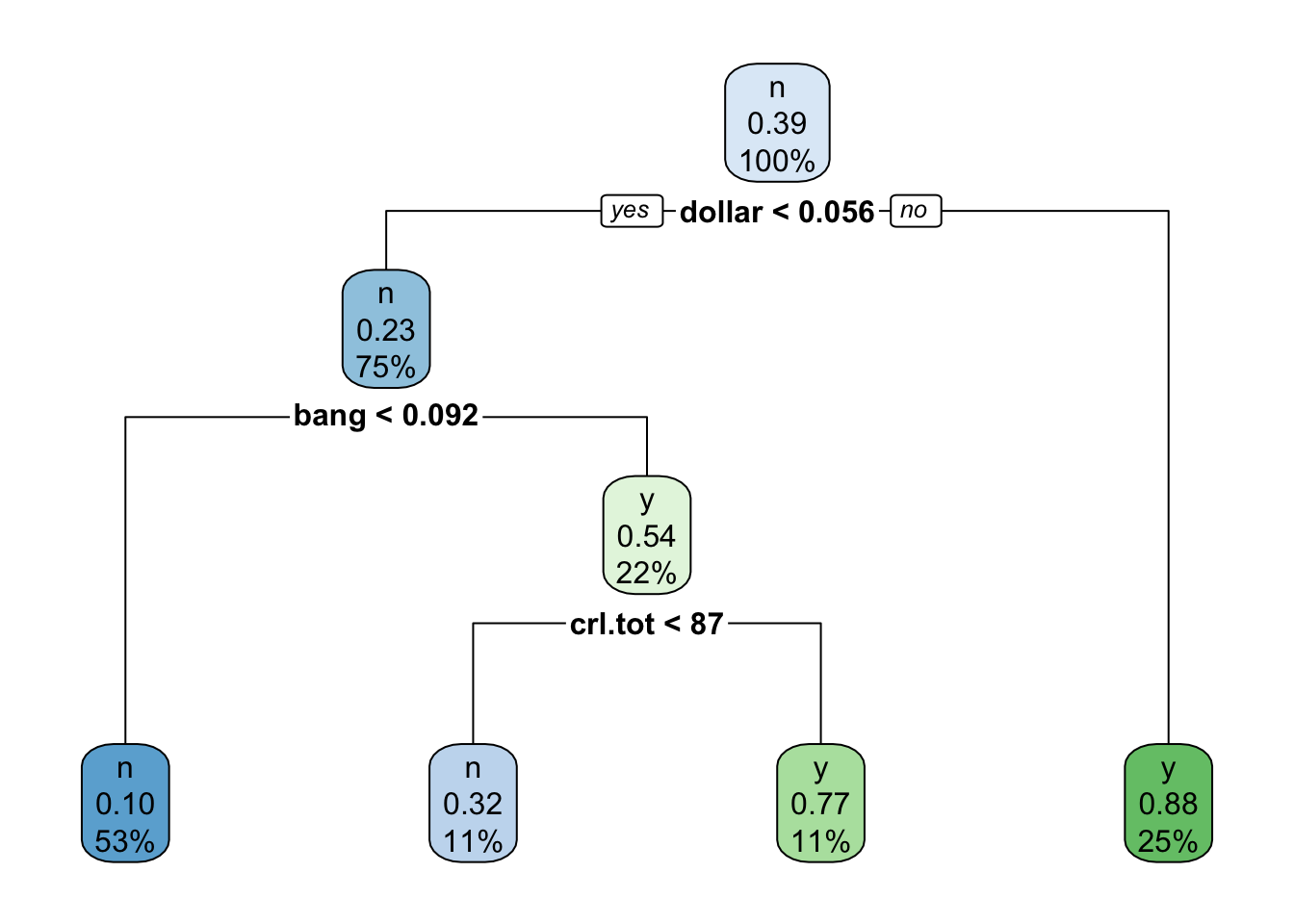
printcp(tree)##
## Classification tree:
## rpart(formula = yesno ~ ., data = train)
##
## Variables actually used in tree construction:
## [1] bang crl.tot dollar
##
## Root node error: 900/2305 = 0.39046
##
## n= 2305
##
## CP nsplit rel error xerror
## 1 0.474444 0 1.00000 1.00000
## 2 0.074444 1 0.52556 0.56556
## 3 0.010000 3 0.37667 0.42111
## xstd
## 1 0.026024
## 2 0.022128
## 3 0.019773plotcp(tree)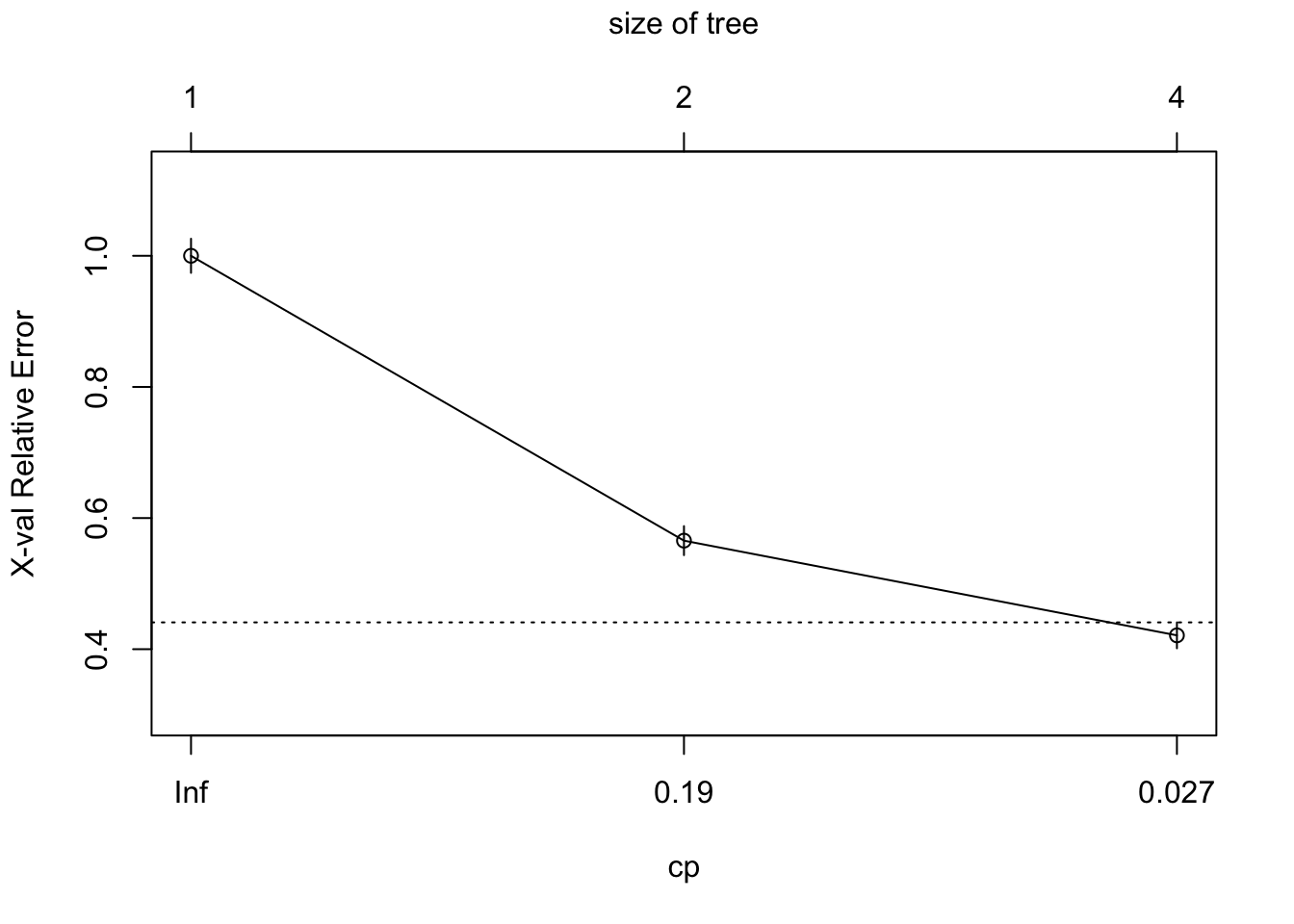
# print confusion matrix of your model on training dataset
p <- predict(tree, train, type = "class")
confusionMatrix(p, train$yesno, positive="y")## Confusion Matrix and Statistics
##
## Reference
## Prediction n y
## n 1278 212
## y 127 688
##
## Accuracy : 0.8529
## 95% CI : (0.8378, 0.8671)
## No Information Rate : 0.6095
## P-Value [Acc > NIR] : < 2.2e-16
##
## Kappa : 0.6857
##
## Mcnemar's Test P-Value : 5.061e-06
##
## Sensitivity : 0.7644
## Specificity : 0.9096
## Pos Pred Value : 0.8442
## Neg Pred Value : 0.8577
## Prevalence : 0.3905
## Detection Rate : 0.2985
## Detection Prevalence : 0.3536
## Balanced Accuracy : 0.8370
##
## 'Positive' Class : y
## # ROC curve
p1 <- predict(tree, test, type="prob")
p1 <- p1[,2] # extract y information
r <- multiclass.roc(test$yesno, p1, percent = TRUE)
roc <- r[["rocs"]]
r1 <- roc[[1]]
plot.roc(
r1,
print.auc = TRUE,
auc.polygon = TRUE,
grid = c(0.1, 0.2),
grid.col = c("green", "red"),
max.auc.polygon = TRUE,
auc.polygon.col = "lightblue",
print.thres = TRUE,
main = "ROC Curve"
)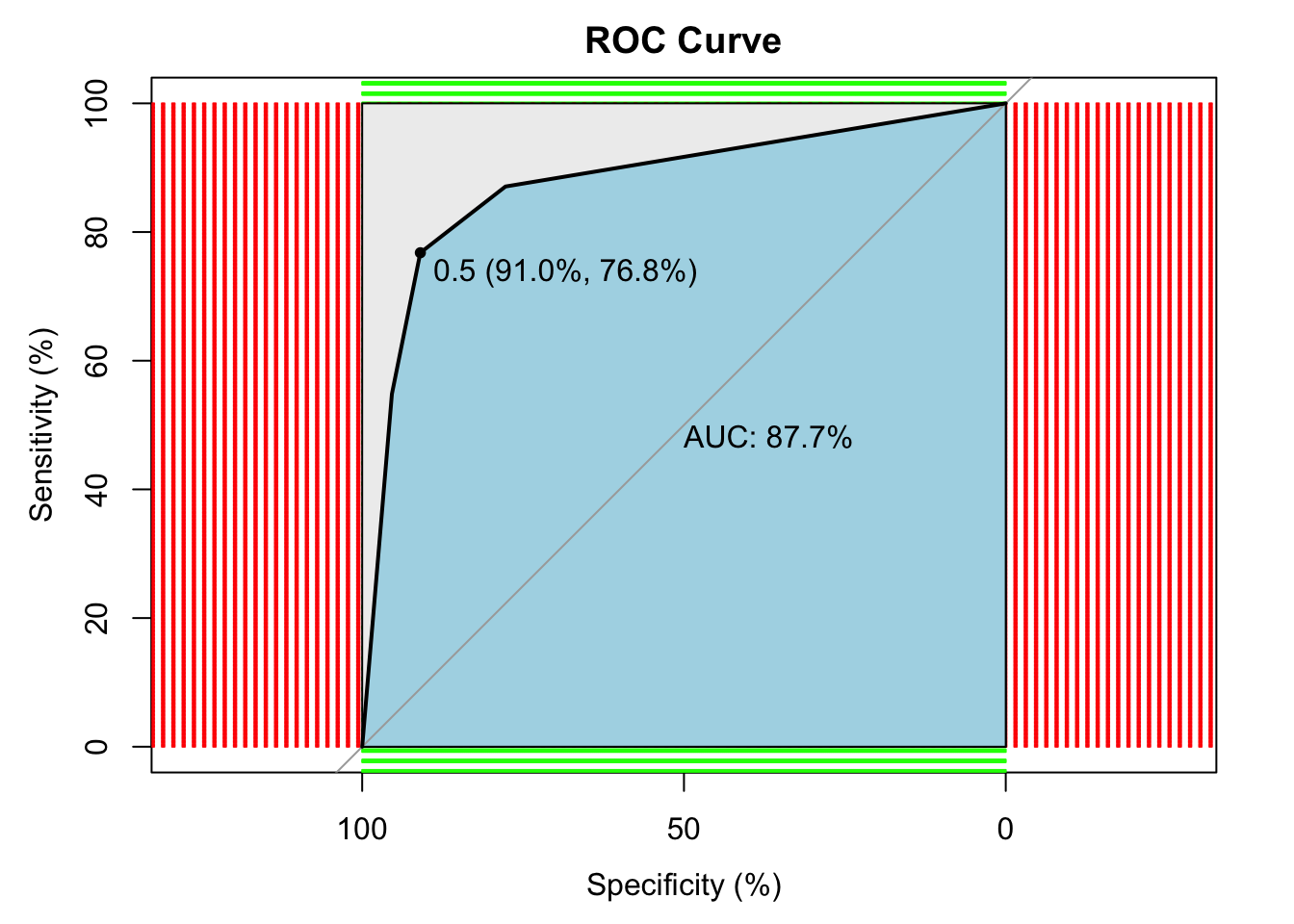 ## Regression Tree
## Regression Tree
data("BostonHousing")
mydata <- BostonHousing
str(mydata)## 'data.frame': 506 obs. of 14 variables:
## $ crim : num 0.00632 0.02731 0.02729 0.03237 0.06905 ...
## $ zn : num 18 0 0 0 0 0 12.5 12.5 12.5 12.5 ...
## $ indus : num 2.31 7.07 7.07 2.18 2.18 2.18 7.87 7.87 7.87 7.87 ...
## $ chas : Factor w/ 2 levels "0","1": 1 1 1 1 1 1 1 1 1 1 ...
## $ nox : num 0.538 0.469 0.469 0.458 0.458 0.458 0.524 0.524 0.524 0.524 ...
## $ rm : num 6.58 6.42 7.18 7 7.15 ...
## $ age : num 65.2 78.9 61.1 45.8 54.2 58.7 66.6 96.1 100 85.9 ...
## $ dis : num 4.09 4.97 4.97 6.06 6.06 ...
## $ rad : num 1 2 2 3 3 3 5 5 5 5 ...
## $ tax : num 296 242 242 222 222 222 311 311 311 311 ...
## $ ptratio: num 15.3 17.8 17.8 18.7 18.7 18.7 15.2 15.2 15.2 15.2 ...
## $ b : num 397 397 393 395 397 ...
## $ lstat : num 4.98 9.14 4.03 2.94 5.33 ...
## $ medv : num 24 21.6 34.7 33.4 36.2 28.7 22.9 27.1 16.5 18.9 ...# Data partition
set.seed(1234)
ind <- sample(2, nrow(mydata), replace = T, prob = c(0.5, 0.5))
train <- mydata[ind == 1,]
test <- mydata[ind == 2,]
tree <- rpart(medv ~., data = train)
rpart.plot(tree)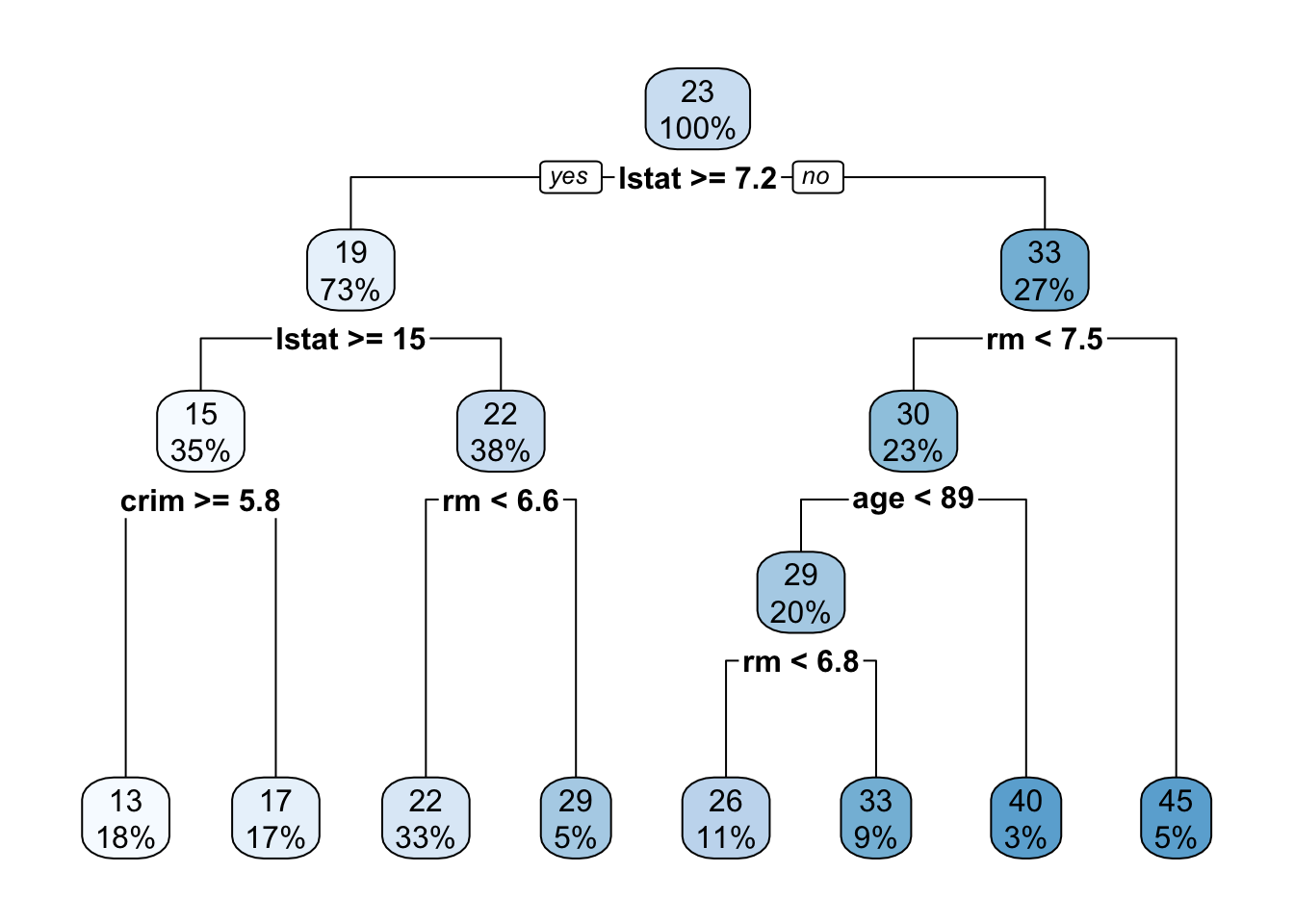
printcp(tree)##
## Regression tree:
## rpart(formula = medv ~ ., data = train)
##
## Variables actually used in tree construction:
## [1] age crim lstat rm
##
## Root node error: 22620/262 = 86.334
##
## n= 262
##
## CP nsplit rel error xerror
## 1 0.469231 0 1.00000 1.01139
## 2 0.128700 1 0.53077 0.62346
## 3 0.098630 2 0.40207 0.51042
## 4 0.033799 3 0.30344 0.42674
## 5 0.028885 4 0.26964 0.39232
## 6 0.028018 5 0.24075 0.37848
## 7 0.015141 6 0.21274 0.34877
## 8 0.010000 7 0.19760 0.33707
## xstd
## 1 0.115186
## 2 0.080154
## 3 0.076055
## 4 0.069827
## 5 0.066342
## 6 0.066389
## 7 0.065824
## 8 0.065641plotcp(tree)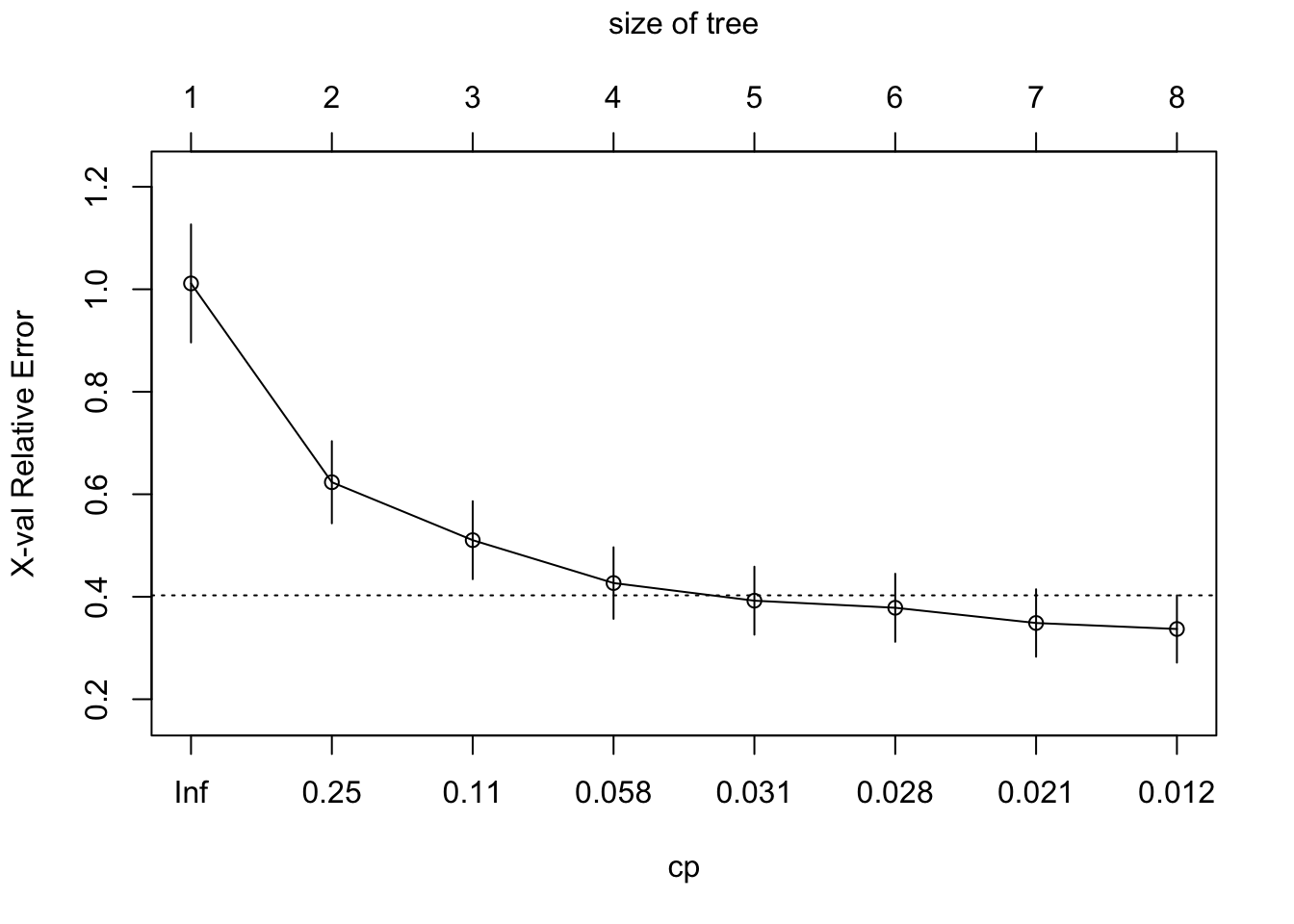
# predict
p <- predict(tree, train)
# RMSE
(sqrt(mean((train$medv - p)^2)))## [1] 4.130294# R squared
(cor(train$medv, p))^2## [1] 0.8024039In the regression model, the r square value is 80% and RMSE is 4.13, not bad at all.. In this way, you can make use of Decision classification regression tree models.
5.2 Random Forest
library(mlbench)
data(Sonar)
(head(Sonar))## V1 V2 V3 V4 V5
## 1 0.0200 0.0371 0.0428 0.0207 0.0954
## 2 0.0453 0.0523 0.0843 0.0689 0.1183
## 3 0.0262 0.0582 0.1099 0.1083 0.0974
## 4 0.0100 0.0171 0.0623 0.0205 0.0205
## 5 0.0762 0.0666 0.0481 0.0394 0.0590
## 6 0.0286 0.0453 0.0277 0.0174 0.0384
## V6 V7 V8 V9 V10
## 1 0.0986 0.1539 0.1601 0.3109 0.2111
## 2 0.2583 0.2156 0.3481 0.3337 0.2872
## 3 0.2280 0.2431 0.3771 0.5598 0.6194
## 4 0.0368 0.1098 0.1276 0.0598 0.1264
## 5 0.0649 0.1209 0.2467 0.3564 0.4459
## 6 0.0990 0.1201 0.1833 0.2105 0.3039
## V11 V12 V13 V14 V15
## 1 0.1609 0.1582 0.2238 0.0645 0.0660
## 2 0.4918 0.6552 0.6919 0.7797 0.7464
## 3 0.6333 0.7060 0.5544 0.5320 0.6479
## 4 0.0881 0.1992 0.0184 0.2261 0.1729
## 5 0.4152 0.3952 0.4256 0.4135 0.4528
## 6 0.2988 0.4250 0.6343 0.8198 1.0000
## V16 V17 V18 V19 V20
## 1 0.2273 0.3100 0.2999 0.5078 0.4797
## 2 0.9444 1.0000 0.8874 0.8024 0.7818
## 3 0.6931 0.6759 0.7551 0.8929 0.8619
## 4 0.2131 0.0693 0.2281 0.4060 0.3973
## 5 0.5326 0.7306 0.6193 0.2032 0.4636
## 6 0.9988 0.9508 0.9025 0.7234 0.5122
## V21 V22 V23 V24 V25
## 1 0.5783 0.5071 0.4328 0.5550 0.6711
## 2 0.5212 0.4052 0.3957 0.3914 0.3250
## 3 0.7974 0.6737 0.4293 0.3648 0.5331
## 4 0.2741 0.3690 0.5556 0.4846 0.3140
## 5 0.4148 0.4292 0.5730 0.5399 0.3161
## 6 0.2074 0.3985 0.5890 0.2872 0.2043
## V26 V27 V28 V29 V30
## 1 0.6415 0.7104 0.8080 0.6791 0.3857
## 2 0.3200 0.3271 0.2767 0.4423 0.2028
## 3 0.2413 0.5070 0.8533 0.6036 0.8514
## 4 0.5334 0.5256 0.2520 0.2090 0.3559
## 5 0.2285 0.6995 1.0000 0.7262 0.4724
## 6 0.5782 0.5389 0.3750 0.3411 0.5067
## V31 V32 V33 V34 V35
## 1 0.1307 0.2604 0.5121 0.7547 0.8537
## 2 0.3788 0.2947 0.1984 0.2341 0.1306
## 3 0.8512 0.5045 0.1862 0.2709 0.4232
## 4 0.6260 0.7340 0.6120 0.3497 0.3953
## 5 0.5103 0.5459 0.2881 0.0981 0.1951
## 6 0.5580 0.4778 0.3299 0.2198 0.1407
## V36 V37 V38 V39 V40
## 1 0.8507 0.6692 0.6097 0.4943 0.2744
## 2 0.4182 0.3835 0.1057 0.1840 0.1970
## 3 0.3043 0.6116 0.6756 0.5375 0.4719
## 4 0.3012 0.5408 0.8814 0.9857 0.9167
## 5 0.4181 0.4604 0.3217 0.2828 0.2430
## 6 0.2856 0.3807 0.4158 0.4054 0.3296
## V41 V42 V43 V44 V45
## 1 0.0510 0.2834 0.2825 0.4256 0.2641
## 2 0.1674 0.0583 0.1401 0.1628 0.0621
## 3 0.4647 0.2587 0.2129 0.2222 0.2111
## 4 0.6121 0.5006 0.3210 0.3202 0.4295
## 5 0.1979 0.2444 0.1847 0.0841 0.0692
## 6 0.2707 0.2650 0.0723 0.1238 0.1192
## V46 V47 V48 V49 V50
## 1 0.1386 0.1051 0.1343 0.0383 0.0324
## 2 0.0203 0.0530 0.0742 0.0409 0.0061
## 3 0.0176 0.1348 0.0744 0.0130 0.0106
## 4 0.3654 0.2655 0.1576 0.0681 0.0294
## 5 0.0528 0.0357 0.0085 0.0230 0.0046
## 6 0.1089 0.0623 0.0494 0.0264 0.0081
## V51 V52 V53 V54 V55
## 1 0.0232 0.0027 0.0065 0.0159 0.0072
## 2 0.0125 0.0084 0.0089 0.0048 0.0094
## 3 0.0033 0.0232 0.0166 0.0095 0.0180
## 4 0.0241 0.0121 0.0036 0.0150 0.0085
## 5 0.0156 0.0031 0.0054 0.0105 0.0110
## 6 0.0104 0.0045 0.0014 0.0038 0.0013
## V56 V57 V58 V59 V60 Class
## 1 0.0167 0.0180 0.0084 0.0090 0.0032 R
## 2 0.0191 0.0140 0.0049 0.0052 0.0044 R
## 3 0.0244 0.0316 0.0164 0.0095 0.0078 R
## 4 0.0073 0.0050 0.0044 0.0040 0.0117 R
## 5 0.0015 0.0072 0.0048 0.0107 0.0094 R
## 6 0.0089 0.0057 0.0027 0.0051 0.0062 Rset.seed(12)
model <- train(
Class ~.,
data = Sonar,
method = "ranger"
)print(model)## Random Forest
##
## 208 samples
## 60 predictor
## 2 classes: 'M', 'R'
##
## No pre-processing
## Resampling: Bootstrapped (25 reps)
## Summary of sample sizes: 208, 208, 208, 208, 208, 208, ...
## Resampling results across tuning parameters:
##
## mtry splitrule Accuracy Kappa
## 2 gini 0.8078699 0.6108857
## 2 extratrees 0.8188579 0.6341083
## 31 gini 0.7751013 0.5455448
## 31 extratrees 0.8275348 0.6496807
## 60 gini 0.7676651 0.5302055
## 60 extratrees 0.8221403 0.6387246
##
## Tuning parameter 'min.node.size' was
## held constant at a value of 1
## Accuracy was used to select the
## optimal model using the largest value.
## The final values used for the model
## were mtry = 31, splitrule =
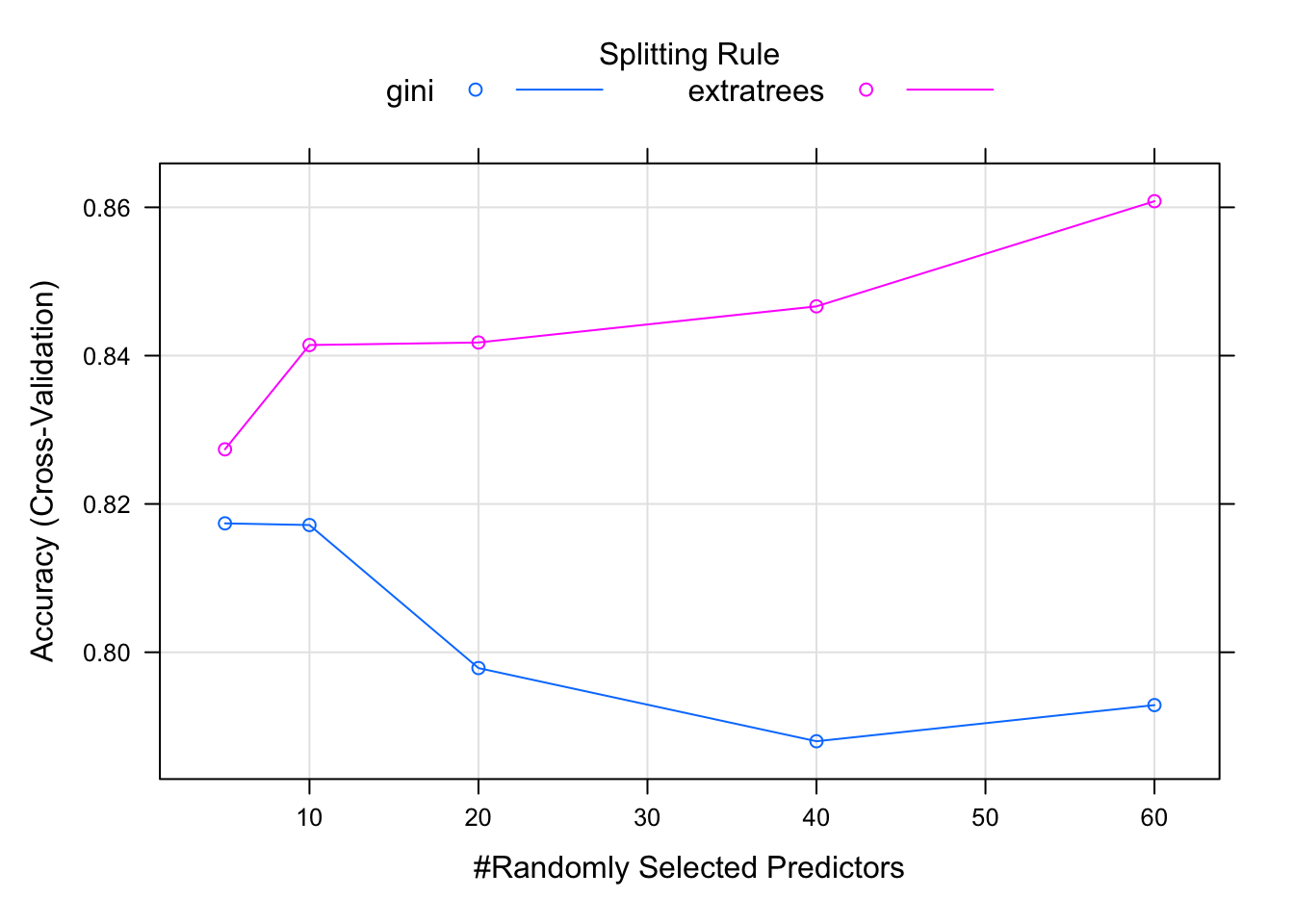
## extratrees and min.node.size = 1.plot(model)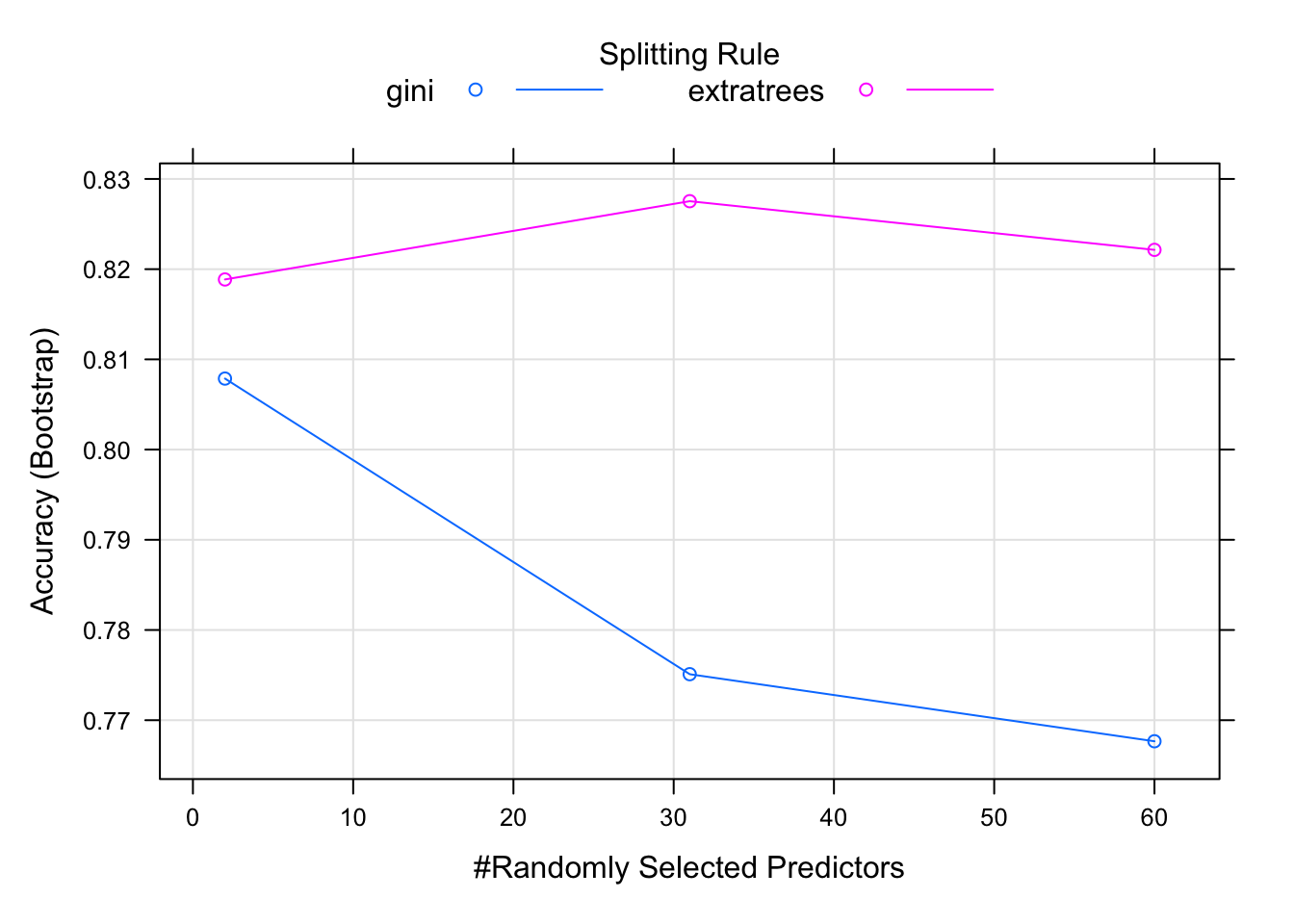 Tune hyperparameters:
Tune hyperparameters:
set.seed(42)
myGrid <- expand.grid(
mtry = c(5, 10, 20, 40, 60),
splitrule=c("gini", "extratrees"),
min.node.size = 1
)
model <- train(
Class ~ .,
data = Sonar,
method = "ranger",
tuneGrid = myGrid,
trControl = trainControl(
method = "cv",
number = 5,
verboseIter = FALSE
)
)
print(model)## Random Forest
##
## 208 samples
## 60 predictor
## 2 classes: 'M', 'R'
##
## No pre-processing
## Resampling: Cross-Validated (5 fold)
## Summary of sample sizes: 166, 167, 167, 167, 165
## Resampling results across tuning parameters:
##
## mtry splitrule Accuracy Kappa
## 5 gini 0.8173838 0.6297111
## 5 extratrees 0.8273668 0.6497566
## 10 gini 0.8171569 0.6305735
## 10 extratrees 0.8414310 0.6791146
## 20 gini 0.7978716 0.5908457
## 20 extratrees 0.8417740 0.6792866
## 40 gini 0.7879994 0.5727742
## 40 extratrees 0.8466467 0.6897164
## 60 gini 0.7928774 0.5822691
## 60 extratrees 0.8608271 0.7187262
##
## Tuning parameter 'min.node.size' was
## held constant at a value of 1
## Accuracy was used to select the
## optimal model using the largest value.
## The final values used for the model
## were mtry = 60, splitrule =
## extratrees and min.node.size = 1.plot(model)